All about Concurrency in Swift - Part 2: The Future
Posted on July 22, 2017
In the first part of this series we have seen what you’ll have to deal with when working with concurrency, how to reason about some typical multithreading problems, what you’ll need to pay special attention to, and we’ve also looked into some of the traditional instruments we have at our disposal when writing Swift applications.
This time we’ll look into what the future could have in store for us in one of the next major releases of Swift.
We’ll analyze some popular paradigms and abstractions used in other programming languages highlighting their strengths and weaknesses, trying to envision how and if they could fit in the overall design of the Swift language.

This article should give you the introduction you’ll need to take part in the discussions on swift-evolution that will revolve around introducing native concurrency functionalities in a future release of Swift and give you a few pointers to start experimenting with new paradigms using the open source libraries that are already available.
Some of these paradigms will still tackle directly the problems related to sharing resources in a multithreaded environment, while others will address the same underlying issues proposing a better way to handle asynchronous tasks guaranteeing that each one will operate without external side effects.
Most languages provide a basic set of common concurrency primitives you’ll find everywhere (locks, semaphores, conditions, etc…) but then select a few specific concurrency paradigms to define their own idiomatic approach.
Some of the paradigms that will be described here could be suitable to be included in the Swift’s standard library sooner or later, while others will probably never be.
Each concurrency model has its supporters and detractors and the community is usually very polarized. This article will not discuss my personal preferences, I’ll try to give you a good overview of the most popular models and I recommend you to invest some time in testing them to see how they fare in the real world, maybe building some throwaway application.
I’ll make frequent references to other languages throughout the article and will include some code samples in languages you may not be familiar with, but don’t worry, I’ll explain syntax quirks when necessary.
Contents
- Memory Model and Standard Library
- Futures and Promises
- Async/Await
- STM: Software Transactional Memory
- The Actor Model
- Communicating Sequential Processes: Channels
- Swift: Where are we now
- A few words on Kotlin
- Closing Thoughts
Memory Model and Standard Library
In this section we’ll take a look at some areas of the Swift language and its runtime that could be improved from the point of view of concurrency without introducing new paradigms.
As described in the first part, Swift does not provide substantial concurrency guarantees and it hasn’t really defined a memory model similar to what you could find elsewhere.
We know that global variables are initialized atomically for example, but concurrent read/write or multiple writes to the same variable are still classified under undefined behaviour, the developer will have to guard those critical sections to avoid concurrent variable modifications.
The proposal SE-0176 addresses this issue proposing that modifications to a variable must be excluvive and should not happen at the same time of other accesses to that variable. Enforcing exclusivity would allow only reads to happen at the same time while forcing writes to be performed in isolation without other threads trying to read or modify the same variable half way through the original write.
Exclusivity could be guaranteed statically during compilation, checking your code for possible invalid accesses to shared variables, or could be enforced dynamically while your program is running keeping track of the access state of your variables.
The proposal describe this problem and discusses what exclusivity entails for different types, but it’s also part of a bigger effort to make Swift’s handling of memory more safe and predictable described in the Ownership Manifesto.
I will not try to dissect this complex document here, if you are interested in knowing more, I recommend to put aside some time (and maybe grab a cup of coffee or tea) and slowly delve into it.
The functionalities described in the manifesto will likely lead to the definition of a memory model, that as described in part one of the series is essential, among other things, to show how the compiler will be allowed to evolve, defining which new optimization strategies will be practicable and which will not.
Now, let’s consider how the data structures of the runtime could be improved and then we’ll talk about managing the data flow with streams and about some lightweight threading functionalities that could help to improve scalability.
Concurrent Data Structures
Some languages have a rich set of data structures included in the default runtime that provide both thread-safe implementations and faster unsafe variants.
The developer will have then to choose each time the right implementation depending on how the object will be used used.
Let’s take a quick look, just for this section, to Java, that more or less ten years ago extended its basic data structures to provide thread-safe variants.
This was part of a larger effort to give Java something more than the extremely basic concurrency functionalities it had at the time, an effort that resulted in the definition of the JSR-166 specification and its implementation in Java 5.
This extension to the language contained things like locks, semaphores and thread pools that you’ll find in libdispatch or Foundation but also concurrent collections, atomic objects and thread-safe queues that are not among the default data structures available from Swift. The majority of those new features were implemented in a lock-less fashion.
While you could implement on your own a thread safe queue or extend arrays or dictionaries to support concurrency, it could still make sense to include efficient implementations of some of these data structures in the standard library.
In addition to the expected lists, maps and sets that perform modifications atomically guaranteeing that all read operations will always complete correctly (using fine-grained locking) and that we’ll always be able to iterate on them even in presence of concurrent changes, Java also provides Blocking Queues and Double Ended Queues.
Blocking queues are fixed-size FIFO queues that have additional methods that allow to wait for the queue to become non-empty when we want to remove a value or wait for the queue to have some free space when we are adding an element on a full queue. An these queue also have add and remove methods that fail if their preconditions are not met right away or after a specific amount of time.
This data structure is well suited to be employed in producers/consumers scenario, where you have multiple producer threads that generate data that other consumers threads will elaborate.
A simple scenario can be implemented in fifty or so lines of Java:
import java.util.concurrent.*;
class Producer implements Runnable {
private final BlockingQueue<String> queue;
Producer(BlockingQueue<String> q) { queue = q; }
public void run() {
try {
while (true) {
//Create a new string
queue.put(produce());
}
} catch (InterruptedException ex) {}
}
String produce() {
//Do something and return a string
return "";
}
}
class Consumer implements Runnable {
private final BlockingQueue<String> queue;
Consumer(BlockingQueue<String> q) { queue = q; }
public void run() {
try {
while (true) {
//Wait on take() or consume
consume(queue.take());
}
} catch (InterruptedException ex) {}
}
void consume(String data) {
//Do something
}
}
public class Main {
public static void main(String... args) {
BlockingQueue<String> q = new ArrayBlockingQueue<String>(10);
Producer p1 = new Producer(q);
Producer p2 = new Producer(q);
Consumer c1 = new Consumer(q);
Consumer c2 = new Consumer(q);
new Thread(p1).start();
new Thread(p2).start();
new Thread(c1).start();
new Thread(c2).start();
}
}
If you get past the verbosity of the language and those semicolons, this implementation is quite an improvement on the classic locks implementation. This data structure hides away all the gritty details and provides an extremely simple interface.
As we’ll see in a few sections, the basic idea of the blocking queue with finite size will come back again, in another, better, form.
Stream Processing and Parallelism
Now, let me introduce briefly an approach that you could already be sort of familiar with if you have ever used the map and flatMap methods that Swift’s sequences provide.
Swift adds some useful methods to sequences that allow to process their content in a more functional way, turning series of iterations typical of procedural code to a sequence of transformations on some input data:
func getData() -> [String] {
var ret = [String]()
for i in (0..<10000).reversed() {
ret.append("i"+String(i))
}
return ret
}
let res = getData()
.lazy
.map{$0[$0.index(after: $0.startIndex)..<$0.endIndex]}
.flatMap{Int($0)}
.filter{$0 < 100}
for n in res.prefix(5) {
print(n)
}
Each element contained in data sequence will be lazily processed, first removing the initial character from each string and then converting the remaining substring to an integer. Values lower than 100 will be filtered out.
Since we have enclosed the initial sequence in a lazy collection with lazy, and no operations in the sequence require the complete output from the previous step to produce a result, only five elements will be actually processed to produce the 5 integers we’ll print.
Normally, on a non-lazy sequence, these operation would have worked through the whole sequence.
Stream processing is a way to perform multiple sequential computations on a series of values, either consuming a set of data (of any kind), available since the beginning of the processing, or a flow of data that will be progressively available over time (with new values coming in every now and then) processed reactively.
Some languages, like Java 8, Scala and others provide those streaming functionality available with Swift’s sequences and much more through more practical Stream types, that can be obtained wrapping common sequence or collection types but that can be also used to implement streams of data with elements that can become available asynchronously, and that will be processed in a non-blocking way.
Streams have all the familiar functional operators you are familiar with, like map, filter and reduce, and as we did with sequences, multiple steps, each one producing a Stream with intermediate results, are pipelined to obtain the final output.
Parallelism can easily be introduced during stream processing for those operations like map that do not require the whole content of the stream to perform their duty but just execute the same task on each element, without side-effects.
And this is maybe where stream processing shine, you will not need to break your computation in blocks to perform separately those phases that can take advantage of parallel execution on systems with multiple CPUs.
Some stream operations will behave differently when parallel execution will be requested and all of this will just require from the developer some planning about how the data will be used between these multiple steps.
I will not include examples of parallel execution (since I would have to do it in Java, that has the most simple API for streams) but you just need to know that most libraries will wrap streams in a specific parallel stream object that will alter the behavior of some operators transparently.
While there not seem to be traditional stream-oriented Swift libraries (likely for the overlap with what the language already provide), the most pupular libraries that use reactive stream processing are probably the principal Swift reactive frameworks, RxSwift and ReactiveSwift, that under the hood use stream of data or events to handle the asynchronous flow of data typical in mobile/desktop applications.
Coroutines and Green Threads
From the first part of this series, we already know that the concept of executing multiple tasks concurrently predates the general availability of platforms with multiple physical execution units.
But how can we handle the execution of multiple tasks on a single CPU, giving the illusion of simultaneous execution, in a multitasking system?
The software layer responsible for the execution of multiple tasks needs to implement the machinery necessary to share the available CPUs between the currently running tasks to increase utilization, for example to temporarily pause tasks waiting for I/O that leave the CPU idle and execute some other task.
There are two main flavor of multitasking systems, that adopt different approaches for CPU allocation.
Cooperative multitasking allows each running task to decide when to relinquish the CPU, giving complete freedom to the developer on how the resources should be used but increasing the chance that the whole system hangs because one or more tasks are monopolizing the available execution units.
Preemptive multitasking instead, takes this responsibility away from the developer and delegates the job of deciding which task should run to a specific Scheduler component, that schedules tasks depending on their priority, but normally allocates the same slice of CPU time to each one, and perform the necessary context switch when a task has used up all its time slice or is waiting for I/O or is otherwise idle.
The preemptive approach is nowadays used in every modern OS kernel (with wildly different scheduling strategies) to allow the execution of multiple threads and processes, making ample use of interrupts to guarantee good performance when handling I/O.
As we already know, the kernel can manage multiple threads and we can use user-space APIs to make use of these threads in our applications.
Multitasking doesn’t have to be limited to the OS layer, no one stop us from implementing user-space threads if we are so inclined.
But does it make sense to do so? It turns out that, yes, it does.
Kernel-level threads need to guarantee data integrity when performing the context switch, making this operation way more complex than one could initially imagine (multiple steps are involved, from saving a well defined set of registers to adjust the processor privilege level). Furthermore, the initial setup required when creating a new thread and the need for a per-thread stack make the creation of a new thread a relatively costly operation.
While with a small number of threads the costs of creation and context switch are negligible, this does not hold true when we start to have hundred or thousands of active threads simultaneously.
The requirement for a stack local to each thread alone would reduce the number of threads you could create in a real world scenario pretty fast.
For these reasons, we can’t use classic OS threads when we plan to have hundreds of thousands (or way more) of concurrent threads in our application (we’ll see in the next sections why we could need these huge amount of threads).
The common solution to this problem, that you’ll see implemented in many languages, consist in creating lightweight user-space threads.
These threads don’t need the full context switch required by kernel threads to provide a similar functionality and can operate in the context of a single kernel thread without having their own local stacks.
User-space threads can be implemented following both multitasking approaches described above, but most of the times you’ll see an implementation ascribable to the cooperative category, where data integrity is less of an issue since there is no scheduler and the developer decides where to yield control of the CPU and guarantees integrity across context switches.
The system that manages this lightweight threads can be backed by one or more classic kernel threads (organized in a pool) but most implementations tend to employ by default a number of kernel threads equal to the number of hardware CPUs.
Coroutines and Green Threads are two examples of user-space lightweight threads with different characteristics.
Green threads recreate what is available at kernel level, with usual system threads, completely at user level, with a lightweight implementation of threads performing preemptive scheduling with a user level scheduler built from scratch that don’t need to invoke threading system calls to function.
Even if the first implementation of green threads was used in the first releases of Java but was later on abandoned in favor of system threads, green threads are now in vogue again for their scalability properties, after improvements in memory performance in the last decade or so have made their advantages quite evident.
At the moment there are no Swift implementations of green threads, but the important thing to know is that green threads have the same API of normal threads, the developer does not need to do anything to make them work the same way system threads would.
Coroutines implement cooperative multitasking instead, leaving the responsibility to guarantee that a routine will play well with other concurrently running routines to the developer, that will have to include in the code special instructions that will specify when the closure will be ready to be paused to run other routines, giving the illusion of closure running concurrently.
While control of the CPU is usually yielded to the next routine waiting to be run with a specific yield other operations that are normally blocking have the same effect. Examples of this are sleep instructions, blocking operations on files and network and many more. Implementations of coroutines usually provide coroutine-aware versions of those basic operations.
The most serious attempt at implementing coroutines in Swift (even if this is not a pure-Swift implementation since it’s built on top of libdill) is represented by the Venice library that offers them among other features.
Let’s see some basic examples using Venice
let coroutine = try Coroutine {
while true {
performExpensiveComputation()
try Coroutine.yield()
}
}
let printer = try Coroutine {
while true {
try Coroutine.wakeUp(100.milliseconds.fromNow())
print(".")
}
}
try Coroutine.wakeUp(5.second.fromNow())
coroutine.cancel()
printer.cancel()
The first coroutine perform a series of expensive operations in a loop, yielding the control of the CPU to allow other coroutines to execute cooperatively. Other coroutines will do the same, for example breaking up what they need to do in a series of steps and yielding back control periodically if needed.
The second coroutine waits for a non-blocking timer to elapse, yielding back control every time, before printing a dot.
The same wakeUp is used in the main thread to wait for 5 seconds before cancelling both coroutines. Cancelling will result in the coroutine throwing a VeniceError and exiting.
While Venice coroutines don’t return values, other implementations of coroutines could look a bit more like Swift’s generators and returning intermediate values like Yield does. But note that the library has not been updated to Swift 3 and uses system threads, it’s presented here just to give you an idea of how the API would look like.
Here is an example from the documentation that generates the Fibonacci sequence:
let maxFibbValue = 100
let fibbGenerator = Coroutine<Int> { yield in
var (a, b) = (1, 1)
while b < maxValue {
(a, b) = (b, a + b)
yield(a) // Returns `a`, and then continues from here when `next` is called again
}
}
let fibb = AnySequence { fibbGenerator }
for x in fibb {
print(x) // -> 1, 2, 3, 5, 8, 13, 21, 55, 89
}
Could some form of lightweight thread be a useful addition to the Swift language?
Definitely, and these new mechanisms would make the language way more scalable, something essential when developing server applications that deal with the network, an area where languages like Go and Erlang are at the moment a better choice.
And lightweight threads, as we’ll see, could be the scalable base mechanism needed to implement effectively the concurrency paradigms that will be described in the next sections.
Futures and Promises
Let’s now introduce another concept you could already be familiar with from other languages: tracking the execution of asynchronous closures through objects that contain a reference to their future return value (we’ve already seen something similar when discussing OperationQueues).
This pattern is especially useful on platforms that don’t have the luxury of being able to distribute asynchronous calls between multiple threads and, to avoid callback hell, need to provide some practical high level API built on top of some form of cooperative multitasking runtime.
Both Futures and Promises are placeholder for the real return value of a function, their completion status can be checked and handlers can be registered to do something when the return value of the function they refer to will be available or to handle errors.
Our programs can also wait for the value of the future to be available or combine multiple futures in a chain when they are dependent on each other.
But what’s the difference between futures and promises?
If we follow the original nomenclature, futures are a simple container that store a value and can only be read once ready, while promises are objects that manage the life-cycle of a future, performing the transition needed to complete it (normally only once) successfully or not (in presence of errors).
Libraries tend to use one or the other interchangeably.
There are quite a few open source Swift libraries that implement Futures and Promises (and as we’ll see in the next section async/await): PromiseKit, Hydra, then, BrightFutures, Overdrive and many others.
While all these implementations provide the basic features needed to use Futures and Promises (sometime also called Tasks) with more or less the same API, some add extended functionalities that could make you code more concise.
Let’s see an example to understand how Futures and Promises work in practice using Hydra.
Suppose we have a retrieveUserData that retrieves the profile data for a user with a specific numeric id that once done calls a completion handler. Let’s improve the API using Promises and Futures.
func getUserData(for id: Int) -> Promise<UserStruct> {
return Promise<UserStruct>(in: .background, { resolve, reject in
retrieveUserData(id: id, completion: { data, error in
if let error = error {
reject(error)
} else {
resolve(data)
}
})
})
}
getUserData(42).then(.main, {user in
// On successful completion
print("Loaded data for user: \(user.username)")
}).catch(.main, {error in
// On error
print("Error: \(error)")
})
In the example above, the getUserData returns a Promise<UserStruct> object, that is set with a value or an error in the completion handler using either the resolve(value:UserStruct) or reject(error:Error) methods.
We then register a function to be called when the promise will be fulfilled using .then, specifying that the closure should be executed on the main queue. The .catch method handles errors for all promises in a chain.
Yes, promises can be chained and have also a few other useful operators, they are definitely not just a cleaner alternative to callbacks.
We will now define two new functions that returns promises and we’ll chain them together to perform three operations in sequence:
func getPhotos(user: UserData) -> Promise<[Photos]>
func bulkDeletePhotos(photos: [Photos]) -> Promise<Int>
getUserData(42).then(getPhotos)
.then(.bulkDeletePhotos)
.catch{ err in
print("Error while deleting photos: \(err)")
}
After the information about the user have been retrieved, we try to get a list of all the photos of this account and then perform a mass deletion. If any of those operations fails, the final catch block will handle the error.
Promises libraries also provide some operators like: all, any, retry, recover, validate and many others.
Combining these operators, complex logic with multiple nested statements can be turned into something more concise but still keeping a good degree of clarity.
getUserData(42).retry(3)
.validate($0.age > 18)
.then{ user in
print("Username: \(user.username)")
}.always{
print("Done.")
}
This time we’ll try to retrieve information on the user with id 42, retrying on failure at most three times, and if successful we’ll print the username after we have verified that the user is over 18 years old.
Using the always method, we can also add a finalizing closure that will always be executed no matter what happens to the closures that precede it in the chain.
The all and any methods create a composite future that will be fulfilled only when either all or at least one of the underlining futures will complete successfully.
let promises = [40,41,42,43,44,45].map {return getUserData($0)}
all(promises).then {users in
print("All \(users.count) users retrieved!")
}.catch {err in
print("Error: \(err)")
}
any(promises).then {users in
print("At least some users retrieved!")
}
While these basic functionalities are common among different implementations, other methods, that for example allow to introduce delays along a chain or that perform additional transformations, could be available.
Async/Await
Now let’s talk about the Async/Await functionality, that is quite popular lately since it has been finally added to Javascript in the ES2017 version of the standard, but that was already available in other languages (C# introduced this API first, in release 5.0 a few years ago).
Async/Await can be considered an extension over the basic futures API.
In the mono-thread world of Javascript, futures provided a better alternative to callback nesting, allowing to enclose asynchronous closures in convenient objects that could be used to chain sequential operations, with the side-effect of simplifying stacktrace browsing during debugging.
These new keywords allow to do something that at a first look appears to be only a small improvement over using promises directly: await allows to block execution until a function returning a promise completes and async allows to annotate functions that during their execution wait for completion of one or more futures.
But let’s see a simple example in Javascript that makes use of both keywords:
async function getUserProfileImageUrl(id) {
let user = await getUserData(id);
let img = await getImageData(user.imageId)
return img.url;
}
With futures we could have obtained a reference to the UserData structure and to ImageData in a series of then closures extracting the URL as last step.
Using Async/Await this asynchronous code looks more like classic synchronous code, an improvement from the point of view of aesthetic but something that could have been replicated waiting in a blocking way for the fulfillment of those two promises.
But look at this from another point of view.
With Async you are also delimiting a context that contains asynchronous calls and with Await you are clearly marking where the execution will stop waiting for a result.
These two information would be extremely useful to implement some form of cooperative multitasking under the hood, and this is what is likely to happen in the context of Javascript in most implementations.
That wait will thus be a non-blocking wait in most of the implementations, with every await function being still executed in sequence, as we saw in the first part of the series, waiting in a non-blocking way is useful when you need to perform I/O or just to increase CPU/resources utilization.
Let’s go back to Swift with some examples with Hydra, but int this case too, other libraries provide a mostly identical API.
let asyncFunc = async({
let user = try await(getUserData(42))
let photos = try await(getPhotos(user))
let success = try await(bulkDeletePhotos(photos))
})
The async block will be executed in the .background thread as the await functions, that run in the context in which they are called.
Additionally, Hydra and other libraries allows to return a promise from within the async block so that you’ll be able to use all the operators seen in the previous section or just simply chain the block with other promises.
How is the failure of a promise handled with async/await?
To handle errors, await calls are usually surrounded by a catch statement, in Javascript but also in the Swift libraries listed above, since as you could have guessed , the try in the previous sample is a sign that an Error will be thrown by await when a promise completes with a failure.
So, for most libraries you’ll be able to catch errors adding a do/catch inside the async block.
If you are interested in learning more about async/await I recommend you to check out the opensource libraries listed above and look under the hood at how the various functions have been implemented.
STM: Software Transactional Memory
In this section we’ll take a look at Clojure, a LISP language running on the JVM that is usually a good source of interesting ideas.
If you want to know more about languages of the LISP family, check out the article I wrote a while ago about implementing a LISP from scratch in Swift, that will guide you through the implementation of a minimal LISP while describing the fundamental components of an interpreter.
Pure functional languages do not allow mutable data or the use of mutable state and as such are inherently thread-safe. If there is no mutable memory that needs to be protected from concurrent access, the problems of concurrency are already solved.
Clojure is an impure functional languages, and manages mutable data through immutable and persistent data structures that are concurrency-aware.
Managing mutability with immutable structures may seem a contradiction until you grok the meaning of the term persistent in this context.
Quoting the article that coined the term:
Ordinary data structures are ephemeral in the sense that making a change to the structure destroys the old version, leaving only the new one. We call a data structure persistent if it supports access to multiple versions. The structure is partially persistent if all versions can be accessed but only the newest version can be modified, and fully persistent if every version can be both accessed and modified.
You could be already familiar with the mechanism of Copy-On-Write, used profusely in Swift, that speeds up the copy of a value when it’s reassigned performing a real copy only when one of the clones of the original value is modified, saving memory and avoiding pointless copying.
In other words, when a data structure that supports COW get copied to a new variable, the new variable will still point to the original area of memory, until a real copy of the original content is triggered by an attempt to change it.
Persistent data structures take this idea a step further and try to share with the original value the part of its structure that didn’t change after the update to perform something akin to a selective copy. All of this with the guarantee that the original memory content will be untouched and still accessible through the other references.
The image below shows a simple example of persistent list, that highlights how the actual copy is performed only when the original data structure will become unusable because the last element down the chain will not be needed anymore.
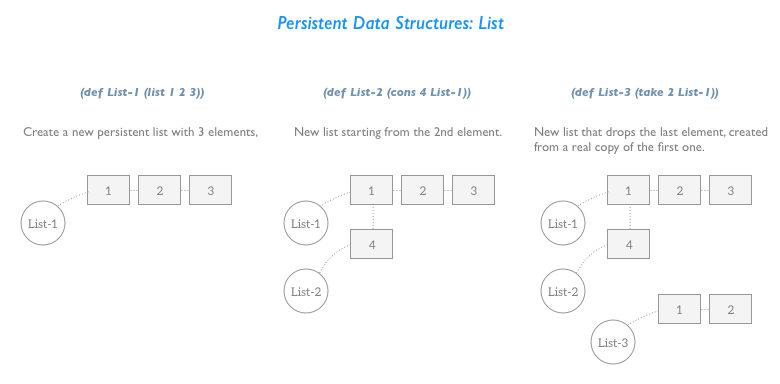
Similarly to COW variables, using persistent data structure has the effect of isolating changes to the reference on which they were applied.
This property is available with all the basic collection types in Clojure and in addition to this, transient, read-only views of persistent data structures can be created in those scenarios where mutability is not needed.
Clojure guarantees thread-safety with different mechanisms building upon persistence through 4 container primitives: Vars, Refs, Atoms and Agents.
The most interesting and most sophisticated are Refs that are an integral component of a system based on Software Transactional Memory.
STM is based on the idea of grouping a series of operations on mutable variables, that need to happen atomically, in a single transaction that is guaranteed to be executed completely or not at all. You could already be familiar with this concept from the world of databases.
Multiple transactions can be executed concurrently but they will never be allowed to interfere with each other, transactions that try to perform conflicting modifications on the same set of data will simply fail and retried by the STM runtime.
Refs contains the objects that can be modified during a transaction and they can be either dereferenced to obtain the value they contain or modified setting a new value or executing a function that alters the current value.
(def counter (ref 0))
(def counter2 (ref 0))
(deref counter) // Dereferenced -> 0
(dosync
(alter counter inc)
(alter counter2 inc)
)
Let me just do a quick and dirty recap of the LISP notation, each couple of parenthesis contain a series of terms that define a symbolic expression. These expression are written in prefix notation, where the first element of this list of terms is an operator and the rest are operands. A sum of two integers would be expressed as (+ 1 2). As said above, check out this article if you want to know more.
In that example we defined two Refs to an integer variable named counter and counter2 and then alter their value in a transaction enclosed in a dosync block, incrementing them.
Both values will always contain the same number regardless of how much contention there will be on those two Refs but when run concurrently, for example with a few threads that just try to execute the transaction, a good amount of those transaction will fail (silently) and will be retried automatically and transparently.
STM implementations are usually lock-free and as such scale better that alternative solutions based on the classic locks we saw in part one, and as you can see there is not much else to do other than defining the content of the transaction.
There are just a few implementation of STM in Swift with varying degree of sophistication, like Typelift’s Concurrent and Swift STM.
Let’s see how STM looks with Concurrent using the bank account example, straight from their documentation:
typealias Account = TVar<UInt>
/// Some atomic operations
func withdraw(from account : Account, amount : UInt) -> STM<()> {
return account.read().flatMap { balance in
if balance > amount {
return account.write(balance - amount)
}
throw TransactionError.insufficientFunds
}
}
func deposit(into account : Account, amount : UInt) -> STM<()> {
return account.read().flatMap { balance in
return account.write(balance + amount)
}
}
func transfer(from : Account, to : Account, amount : UInt) -> STM<()> {
return from.read().flatMap { fromBalance in
if fromBalance > amount {
return withdraw(from: from, amount: amount)
.then(deposit(into: to, amount: amount))
}
throw TransactionError.insufficientFunds
}
}
The TVar type represent a container that supports the transactional memory interface and in this case it contains an integer with the account balance and the withdraw, deposit and transfer functions change its value or perform a transfer between different accounts.
As you can see in the transfer function, a transaction is built concatenating multiple operations:
let alice = Account(200)
let bob = Account(100)
let finalStatement =
transfer(from: alice, to: bob, amount: 100)
.then(transfer(from: bob, to: alice, amount: 20))
.then(deposit(into: bob, amount: 1000))
.then(transfer(from: bob, to: alice, amount: 500))
.atomically()
The transaction will be executed only when atomically() is called.
To learn more about STM and how it can be implemented I recommend the article Beautiful Concurrency from Simon Peyton Jones.
The Actor Model
In the first part of this series, we dealt with concurrency using locking primitives and more complex APIs based on the use of pool of threads to control multiple accesses to shared memory and to perform concurrent operations.
Locks and derivatives are the most basic primitives we have at how disposal, through them we can limit the access to code that modifies a shared area of memory imposing entry checks and regulating the execution flow of multiple threads.
Locks does not scale well, with increasing number of threads or with the same memory (or most of the times, data structure) shared in too many places reasoning about the state of your programs can become quite challenging.
High level APIs like DispatchQueue allows to model concurrent operations in a way that is easy to reason about but are based on threads, a low level primitive that as we saw in the green threads section is quite resource hungry when you consider the cost of the context switch and the memory usage.
And everything we have described until now does not really take into consideration that our programs could need to synchronize their state across multiple machines and between multiple instances of our application.
Wouldn’t be nice to be able to write concurrent code that could nearly transparently be able to run in a distributed environment without any modification?
To support this additional use case we need to introduce new paradigms based on an idea that you are already familiar with from the days of Objective-C: Message Passing.
This approach allows to handle concurrency without sharing memory (implicitly solving a lot of the concurrency issues we’ve seen until now) through higher level constructs that handle the exchange of messages between concurrent entities operating in isolation from each other.
We’ll take a look at two paradigms based on message passing: The Actor Model and Communicating Sequential Processes.
Implementations of the actor model can be found in various languages, from the most notable, Erlang, to languages like Java that support the paradigm through external libraries like Akka.
An actor is an object that provides various services through an interface that processes asynchronous messages and that maintains a mutable internal state (if the actor is stateful instead of stateless) that is never shared with the actor’s clients to guarantee thread-safety.
In most implementations, direct messages are received in the same order they were sent and are always processed sequentially since, internally, actors are single-threaded (but not usually backed by a real system thread) and as such, message processing can be considered as an atomic operation.
But messages are not actually sent directly to an actor object.
Each actor has its own Mailbox, a queue that stores the asynchronous messages directed to a specific actor, working as a buffer for incoming messages. A mailbox can have additional characteristics that change the way the actor receives messages, it could for example, limit the number of messages it holds or introduce the concept of message priority.
An actor receives messages but can also send messages to other actors if it knows their address or if when it needs it, it can create a new actor instance for the destination actor. This property is known as locality.
Every message has a reference to its sender, so that is always possible to reply back maintaining locality.
A system that uses the actor model is made up by a network on multiple actors with various functionalities, that communicate with each other constantly. Since each actor can create new actors, the topology of the network is dynamic. Smaller network of actors can be interconnected to build bigger systems.
Since there are no mature Swift libraries implementing the actor model, let’s see some concrete examples using Scala, a language running on the JVM with lot’s of interesting features, and the Akka library.
We’ll create a counter actor, that will maintain an integer value as its state and that will expose to other actors methods to increment this counter or get its value.
No concurrent access to this integer value will be possible, the actor will implicitly take care of that. This is functionally equivalent to having an integer counter protected by multiple accesses through a lock or some other equivalent basic concurrency primitive.
import akka.actor.Actor
import akka.actor.Props
import akka.event.Logging
class Counter extends Actor {
var count = 0
def receive = {
case "incr" => count += 1
case "get" => sender() ! count
case _ => println("Unknown message received")
}
}
class Main extends Actor {
val counter = context.actorOf(Props[Counter], “counter”)
counter ! “incr”
counter ! “incr”
counter ! “incr”
counter ! “get”
def receive = {
case count: Int =>
println(s“count was $count”)
context.stop(self)
case _ => println("Unknown message received")
}
}
Above we are defining two actors, the Counter actor that will manage the mutable count and the Main actor that we’ll use to send command to the counter.
The receive method contains a message loop that defines the behavior of the actor, associating at each message string a closure that will be executed every time that specific message is executed.
Akka requires that all the loops must be exhaustive, so, in this case we’ll have to add a final catch all case to our receive loops. Using something akin to enums with associated values (i.e. Scala’s case classes) and specifying all the cases would remove this requirement. Other implementations (e.g. Erlang actors) do not require exhaustiveness.
An interesting feature of actors is the ability to alter their behavior while they are running. Multiple message loops can be defined and the actor will be able to switch between them selecting one of them as active loop.
In the sample above, the Counter replies to incr and get, respectively incrementing the local counter or sending the value of the counter to the actor that sent the message.
In this example all the messages are sent in “fire and forget” mode using the ! operator, that sends the message asynchronously and returns right away. Alternatively, messages can be sent encapsulating the status of the call into a future.
The Main actor creates a Counter actor and then proceeds to incrementing the counter three times before retrieving its value. The value is then obtained asynchronously in its receive loop, where the value is printed before the actor stops itself.
Now that we’ve got this basic example down, let’s talk again about behaviors.
The fact that multiple receive loops can be defined before-hand and then swapped at runtime can be useful to implement a Finite State Machine to manage the various states the actor will find itself during its lifetime.
An actor could for example be started in a uninitialized state and require a series of messages to be configured and perform a transition to its normal running state. Or it could have a more complex logic, easy to represent with a FSM, where every state could be implemented with a different receive loop and where transitions would be performed when specific messages are received. Furthermore, the ability to change the behavior could be used to encapsulate the internal state of stateful actors.
Let’s see a quick example going back to the counter actor, we’ll remove the need for an external integer counter embedding the counter value in the receive loop.
class Counter extends Actor {
def counter(n: Int) = {
case "incr" => context.become(counter(n + 1))
case "get" => sender() ! n
case _ => println("Unknown message received")
}
def receive = counter(0)
}
A simple actor with two states returning two alternating values can be easily defined as follow:
class PingPong extends Actor {
def ping = {
case "get" =>
sender() ! "Ping!"
context.become(pong)
case _ => println("Unknown message received")
}
def pong = {
case "get" =>
sender() ! "Pong!"
context.become(ping)
case _ => println("Unknown message received")
}
def receive = ping
}
Now, we have our system based on a huge number of actors all operating concurrently and processing asynchronous message, how do we handle abnormal errors and fault conditions?
While normal error condition related to the logic of an actor can still be handled through error messages, unexpected exceptions (remember that Scala and Akka run on the JVM) that may crash an actor can’t.
Systems based on actors follow a “let it crash” approach, and focus on bringing back the system to a normal functioning state deciding what to do with components marked as failed, instead of trying to keep components alive stabilizing their state perturbed by an unexpected error.
Actor system are fault tolerant and allow to choose a recovery strategy to make an actor (or a series of actors in a network) fully functional again after a fault.
A failing actor could be for example simply restarted with a clean slate, discarding its internal state, it could be stopped completely or we could just ignore a class of errors and go on as if nothing happened. The strategy you choose depends on the error and what you need to do to bring back the actor to its running state.
What you have read in this section barely scratches the surface of what modern actor systems have to offer, to learn more check out this video with Carl Hewitt, the Akka documentation or read about Erlang’s implementation.
To conclude, we’ve seen that the actor model has a lot of interesting characteristics until now, but it also has some weaknesses.
In some situations, it could be quite hard to model your problem following the rigid actor model and other approaches could be better suited for what you need to do.
When using actors you’ll also need to consider how messages flow in your system and configure accordingly the mailbox of each actor. Failing to do this could lead to mailbox’s overflows.
Actors are also the wrong tool when you want to parallelize sections of your code, that’s not the problem the actor model is trying to solve.
Communicating Sequential Processes: Channels
The Communicating Sequential Process model is another concurrency model based on message passing that, instead of focusing on the objects receiving or sending messages and what they do, revolves around the idea of channels, that compose the infrastructure needed to exchange messages between different entities running concurrently.
A channel can be used to send and receive messages between entities running in different tasks that will use it as a communication channel. You could have for example a task that takes care of centralized logging that exposes its services through a channel that every other task in the system would use.
From the point of view of the implementation, a channel is nothing more than a thread-safe FIFO queue, that can hold multiple messages awaiting to be received if needed(buffered channels).
The sender usually blocks when the channel is full and waits until a receiver removes a message from the list. Conversely, receivers blocks when a queue is empty and wait for new messages. Channels can be closed when they are not needed anymore, unblocking all the senders and receivers that were waiting on that queue.
Implementations of channels have usually a rich API that allows to handle messages from different channels in a single reception block and are usually coupled with some lightweight thread implementation to make the system more scalable.
And channels are usually paired with some form of lightweight threads, either coroutines or green threads, since these two functionality pair quite well together.
A few Swift implementations for CSP channels, each one with a different API and a different set of functionalities, are already available: Venice, Concurrent and Safe.
The only library that also provides coroutines is Venice, but on the other hand has a channel API a bit different from what you’d normally expect and is not a pure-Swift framework. As far as I know there are no Swift implementation of green threads.
The Go programming language is probably the reason behind the recent surge in popularity of CSP channels since channels and goroutines (go’s implementation of coroutines) are the corner stone of its approach to concurrency.
Considering that every Swift implementation available at the moment lacks something (Safe is Swift 2 only, Concurrent and Venice do not support the select statement), I’ll present a few examples in Go, that has a clean and minimalistic API for both channels and goroutines. But I still recommend to check out those libraries since what they have could be enough for your use case.
We’ll create a simple program that defines a channel and uses it to send a string between a goroutine and the main thread. The main thread will wait for the string using the channel and it will just print it once it’s available.
package main
import "fmt"
import "time"
func main() {
messages := make(chan string)
go func(){
time.Sleep(time.Second)
messages <- "Hello!"
}()
msg := <- messages
fmt.Println(msg)
}
In the main function, the entry point of the program, we define a channel that will contain a single string with the make function.
What follows is the declaration of a goroutine that will execute an anonymous closure responsible for sending a string through the channel.
As we said in the Coroutines and Green Threads section, goroutines are just lightweight threads, we could happily create hundred of thousands of them.
After sleeping for a second, the goroutine will send a string message through the channel using the <- operator. Depending on what is on the right side of the operator, it send or receive a message through a channel.
The main thread will block trying to extract a string from the messages channel until the goroutine will send one. Once it gets a hold of one, it will print it.
Optionally, channels can be buffered and be able to store more than one object and they can also be restricted to a specific direction (send-only or receive-only).
They can be used in different ways to coordinate work between a chain of goroutines or to send back results from a background worker goroutine that had some task to execute.
Since most implementations will be based on multiple channels to coordinate multiple goroutines, each one with a different job to perform, a construct able to handle messages from more than one channel in a single place exists, the select block.
package main
import(
"fmt"
"time"
)
func main() {
ch1 := make(chan string, 3)
ch2 := make(chan string, 3)
done := make(chan bool)
go func() {
for i := 0; i < 10; i++ {
ch1 <- "Message from 1"
time.Sleep(time.Second * 1)
}
}()
go func() {
for i := 0; i < 10; i++ {
ch2 <- "Message from 2"
time.Sleep(time.Second * 2)
}
done <- true
}()
go func() {
for {
select {
case msg1 := <- ch1:
fmt.Println(msg1)
case msg2 := <- ch2:
fmt.Println(msg2)
}
}
}()
<- done
}
This time we have three anonymous closures executed in as many goroutines.
The first two will send a string and wait, with the longer second goroutines sending a boolean through a boolean channel when is done with its strings. This channel is used as completion signal of the main thread (not a perfect implementation).
The third goroutines receives the messages checking continuously the two string channels and prints everything it receives. The select block allows to wait on more than one channel and be able to receive all the messages from the channels regardless of the order in which they are sent.
Considering that each wait on a channel would have been otherwise blocking, this new construct is essential, without it channels are instantly a lot less useful.
Proponents of actors and CSP are member of two opposing school of thoughts, so, you’ll rarely found someone advocating the use of both approaches in a language.
Channels have great performance characteristics are way more simple than actors and that can lead to simple and clean architectures sometime.
But in the end they are just blocking queues, they don’t solve any of the concurrency problems described in the first part of the series, and you’ll have to use them as building blocks of more complex mechanisms on your own.
While CSP channels introduce a lot of flexibility compared to the one message queue per task approach of the Actor model and allow to build a network of lightweight processes connected by multiple communication channels, they do not have much to say in regards to fault tolerance.
You will not have something analogous to the independent software components that can be restarted at will available with the actor model.
But probably the greatest weakness of CSP channels is that you’ll be rarely able to structure your program around the use of channels alone without creating convoluted hierarchies of channels.
In most cases, you’ll still need to resort to the basic locks seen in part one.
Swift: Where are we now
Discussions on the future of concurrency on swift-evolution have yet to start, and the community will start introducing the first proposal likely a few months after the release of Swift 4 (assuming that improving concurrency will be one of the goals of Swift 5).
So, until the end of 2017 it’s unlikely that discussions around concurrency will start.
But when it will happen, I expect heated discussions with lot’s of input from the community, on a scale similar to what happened when discussing the access keywords or SE-110.
For now, in addition to the already cited Ownership Manifesto, the only document that touches the subject is this unmaintained draft that contains quite a few interesting ideas.
The document outlines some of the challenges involved in making concurrency more safe and discusses possible approaches to implement Actors, CSP channels and Async/await.
Update 8/17
Chris Lattner wrote his toughts on concurrency in a manifesto and discusses all the topics of this post, check out his take on it. He and Joe Groff also published a proposal for async/await.
A few words on Kotlin
Now let’s talk about concurrency in Kotlin, the de-facto counterpart of Swift on Android.
When using Java interoperability, Kotlin inherits all the concurrency functionalities available in Java, from threads and locks to thread pools and concurrent data structures but since one day Kotlin could not have an underlying JVM to depend on, a new alternative approach to concurrency is in development.
I’m referring to an experimental implementation of some of the paradigms described in the previous sections based on coroutines, that at the moment are distributed as an external kotlinx.coroutines library.
The coroutines library contains implementations of async/await, generators(that I didn’t describe in this article, but that have a structural similarity with Swift’s generators) and channels with support for select.
Swift could follow the same route, instead of choosing one paradigm in particular, multiple options could be offered like in the proposal linked in the previous section, and they could be built on top of some form of lightweight threads.
Closing Thoughts
This article should contain a good overview of the most popular paradigms and should give you enough pointers to experiment and learn further.
We’ve discussed the basic principles behind Promises, Await/Async, STM, Actors and CSP, paradigms that could have a place in the future of Swift, maybe (and I realize I’ve said this more than one time) built leveraging some lightweight mechanism like coroutines or green threads.
And while it’s too soon to speculate which new features will be added to Swift and when, we can all be sure of one thing: concurrency is coming.
Did you like this article? Let me know on Twitter!